자바스크립트 스프레드 문법의 함정

이런 코드를 본 적이 있다면
const arr = [1, 3, 5, 4, 2];
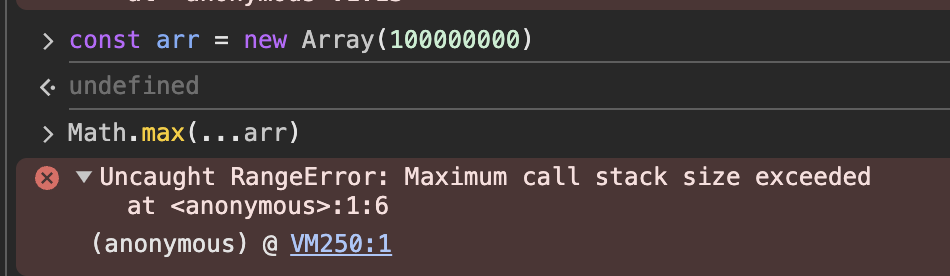
const maxValue = Math.max(...arr);위 코드는 정수로 이루어진 배열 arr의 최댓값을 찾는 코드입니다. Math.max()는 입력받은 매개변수 중 가장 큰 값을 리턴하는 함수로, 직접 입력 데이터를 Math.max(a,b,c, ...)로 풀어쓰는 방법도 있지만 위 코드처럼 스프레드 문법을 이용해 배열을 펼쳐서 넘길수도 있습니다. 이런 방법은 평소에는 크게 문제가 되지 않을 것처럼 보이지만, 과연 모든 상황에서 전혀 문제가 없을까요? 만약 arr의 길이가 100만 개가 넘는 매우 큰 배열이라면 어떨까요?
결론부터 얘기하자면, 아래와 같은 에러 메세지가 뜨게 됩니다.
Uncaught RangeError: Maximum call stack size exceeded
이 글에서는 우리가 Syntax sugar처럼 쓰고 있던 스프레드 문법을 쓸 때 주의해야할 점들을 간단히 적어보려고 합니다.
들어가기에 앞서: 스프레드 문법이란?
스프레드 문법은 ES6에 들어온 기능으로 배열이나 문자열같은 이터러블 데이터의 요소들을 풀어서 열거시켜주는 역할을 합니다. ES9부터는 객체 리터럴에서도(객체는 그 자체로 이터러블이 아닙니다) 스프레드 문법을 쓸 수 있게 되었죠. 이 때 열거되는 요소들은 전부 enumerable한 값들입니다.
const o = {};
Object.defineProperty(o, "a", { value: 1, enumerable: true });
Object.defineProperty(o, "b", { value: 2, enumerable: false });
const oo = { ...o }; // { a: 1 }스프레드 문법의 등장으로 배열과 객체를 다룰때 코드를 더 간결하게 작성할 수 있게 되었습니다. 이 편의성때문에 종종 특정 상황에서 신경써야할 점들을 놓쳐버리기도 합니다.
무엇을 주의해야 하나요
1. 스택 오버플로우
흔히들 스택 오버플로우는 재귀 호출 혹은 프로그래밍 오류로 인한 무한 루프로 호출 스택이 끊임없이 쌓여 발생하는 거라고 생각합니다. 물론 그런 경우가 있긴 하지만, 함수 파라미터로 너무 큰 데이터가 전달되었을 때에도 스택 오버플로우가 일어날 수 있습니다.
왜 그럴까요? 함수가 호출될 때 콜 스택에는 다음과 같은 정보들이 담긴 스택 프레임이 쌓입니다.
- 스코프 체인, 변수 객체, this 바인딩 등 함수 실행 환경에 대한 정보를 담은 실행 컨텍스트
- 함수의 호출 위치 정보 (라인 번호, 파일)
- 인수 (
arguments) - 함수의 리턴 주소 (함수 실행 완료 후 돌아갈 위치)
여기서 주목해야할 것은 인수 부분입니다. 객체나 배열은 콜 스택이 아니라 힙 메모리 영역에 실제 값이 저장되고, 콜 스택에서는 이 값을 가리키는 주소만 저장된다는 점을 혹시 기억하고 계신가요? 따라서 func(arr) 같은 형태로 함수 호출이 일어날 땐 arr이 아주 큰 배열이어도 배열의 값 자체가 아니라 참조값(주소)이 인수로 전달되기 때문에 문제가 일어나지 않습니다. 하지만 스프레드 문법이 적용된다면 어떨까요?
const arr = [1,2,3, ........];
// case 1. arr을 가리키는 참조값만 전달
func(arr);
// case 2. arr의 요소들이 그대로 전달
func(...arr); // == func(1,2,3,4,5, .., ...)해당 데이터를 가리키는 참조값이 아니라 내부 요소들이 전부 함수의 인수로 넘어가게 되고, 각 요소가 문자나 숫자같은 원시값이라면 스택 메모리에 전부 저장됩니다. 이 때 메모리 공간이 넘치면서 스택 오버플로우가 발생하게 되는거죠. 이처럼, 함수의 파라미터로 너무 큰 참조형 데이터를 스프레드 문법으로 넘기게 되면 단 한 번의 함수 호출로도 스택 오버플로우를 발생시킬 수 있습니다.
2. 얕은 복사
ES9부터 객체 리터럴에 스프레드 문법을 적용할 수 있게 되면서 Object.assign()을 썼을 때보다 코드를 더 간결하게 작성할 수 있게 되었습니다. 하지만 가장 최상위 요소들에 대해서만 얕은 복사(shallow copy) 가 일어난다는 점에 주의해야 합니다. 예시 코드를 보겠습니다.
const prevObj = { name: "yesol", jobInfo: { role: "FE", experience: 6 } };
const newObj = { ...prevObj };
prevObj.jobInfo.experience = 7;
console.log(newObj.jobInfo.experience); // 72번째 라인의 스프레드 문법을 통해 newObj의 name 속성엔 'yesol' 원시값 자체가, jobInfo 속성엔 prevObj.jobInfo 가 가리키는 참조값(주소)이 복사되었습니다. name 속성은 값 자체가 복사되었기 때문에 prevObj.name = 'sol' 로 값을 바꿔도 newObj는 전혀 영향을 받지 않습니다. 하지만 jobInfo 속성처럼 그 값이 객체나 배열일 경우 참조값을 복사하기 때문에 prevObj와 newObj 모두 같은 메모리 공간을 바라보게 됩니다. 따라서 위 코드처럼 prevObj.jobInfo의 값을 변경해버리면, newObj의 값도 바뀝니다. 이를 간과하고 코드를 작성하면 데이터가 예상치 못한 흐름으로 변경되어 버그를 일으킬 수 있습니다. 특히나 데이터 불변성을 강조하는 함수형 프로그래밍 관점에서는 더욱 취약한 부분이 되기 쉽죠.
그래서 많은 사람들이 깊은 복사를 제공하는 유틸 함수를 활용하거나(예시로 lodash의 cloneDeep이 있겠네요), 재귀함수를 활용하거나, JSON.parse/stringify 를 이용하곤 합니다. 최근에는 structuredClone 이라는 API가 등장했는데, 과거에는 호환성 이슈로 잘 쓰이지 않았지만 요즘은 IE가 서비스 범위에서 제외되어가고 있는 추세이니 한번 고려해볼만 합니다.
3. 덮어쓰기
객체 리터럴에서 스프레드 문법을 사용할 경우 같은 이름을 가진 속성은 마지막에 들어온 값으로 덮어씌워집니다.
const a = { name: "sol" };
const b = { name: "new-sol" };
const merged = { ...a, ...b }; // { name: 'new-sol' }사실 이 부분은 주의해야할 점이기도 하면서 동시에 리덕스처럼 상태를 불변하게 다루는 코드에서 새로운 상태값 선언시 요긴하게 쓰는 기능이기도 합니다. 먼저 이전 상태 값을 새로운 객체 리터럴에 스프레드 문법으로 풀어놓은 다음, 업데이트된 속성을 마지막에 명시함으로써 기존 데이터 구조는 유지하되 변경된 속성만 최신 값으로 덮어씌워 새로운 상태값을 만드는 거죠.
마치며
이 글에서는 스프레드 문법에 대한 간단한 설명과 사용할 때 주의해야할 점에 대해 정리해보았습니다. 스프레드 문법은 객체 리터럴과 이터러블을 간결한 코드로 다룰 수 있게 해주는 편의성을 제공하지만, 크기가 큰 참조형 데이터를 다룰 때처럼 특정 상황에서는 이슈가 있을 수 있다는 점을 다시 한번 더 짚고 넘어가고 싶습니다. 제가 이 글을 작성한 가장 큰 이유였거든요. 새롭게 ES6를 접한 개발자 분들에게 이 글이 도움이 되길 바라면서 이상으로 글을 마치겠습니다. 감사합니다.